
Category: ✍笔记分享
Cryptography use cases in blockchain technology: zk-SNARKs overview
I am starting to learn and write about cryptography use cases in blockchain technology. I will skip the basic stuff like digital signature, public-key cryptography in general, and look into some specific technologies that are used in some specific cryptocurrencies projects.
I will start with zk-SNARKs in this one. zk-SNARKs stands for zero knowledge Succinct Non-interactive Argument of Knowledge. Zero-knowledge here is exactly the popular protocol in cryptography where a prover can verify that the prover knows certain knowledge to a verifier without revealing it. In cryptocurrencies, zk-SNARKs is a variant of zero knowledge proof that is able to verify a transaction to the nodes without revealing the information about this transaction. This is giving a nice privacy feature to the blockchain world where every transaction is normally publically available. Zcash is an example crypto project that uses zk-SNARKs.
Before going into the technical details, it is worth noticing that zero-knowledge is actually the focus of this protocol in terms of its construction, instead, most efforts of this protocol are on efficiency. Unlike traditional zero knowledge proof that requires frequent communication between the prover and the verifier, zk-SNARKs requires very little communication between the two parties since it is costly in the blockchain world.
So what do zk-SNARKs do exactly? Say Alice creates a transaction and wants to transfer 10 bitcoin to Bob. Alice would need to tell the whole world all about this transaction because the nodes need the information to check whether the transaction is valid. With zk-SNARKs, Alice can prove the transaction is valid without revealing the details of the transaction.
Let’s focus on hiding the amount of the transaction. How can a transaction be verified if the amount is not revealed? zk-SNARKs do so by providing proofs of:
1) the number of coins Alice has equals the number of coins she sends to Bob plus the number of the change (Bitcoin’s UXTO protocol requires all money to be spent in a transaction and the remaining part is the change).
2) the number of coins Alice going to spend is not negative.
3) Alice does have that amount of coins as input.
The first point can be achieved by homomorphic encryption without revealing the number. That is, E(a+b) = E(a) + E(b), where a and b are the money spent and the change. By applying an encryption function that is addition homomorphic, doing addition before encryption and doing encryption before addition outputs the same result, which means a and b do not need to be sent in plain text.
With the first point satisfied, an evil thing Alice can do is to send a negative number to Bob, which will also pass the test of addition. So Alice also needs to prove the number is not negative, in other words, the number is in a certain range. At a rather high level, the range proof needs to be expressed as some polynomials. This was a bit hard to understand for me and it totally worth another article to explain. In short, computable problems can be expressed in polynomials. The verifier can then check whether certain x values in the polynomials correspond to the correct y values. The reason for using polynomials is that, even one simple change in a factor in polynomial results in different y values in almost every corresponding x value, which means a single random check on a certain x value already gives a great guarantee of the correctness of the knowledge.
The last point is to prove that Alice does own that much money. The first method is to use the output from the previous transactions that Alice received as the input of this transaction. As we can imagine, we then have a problem of proving the very first transaction is valid without revealing the number, otherwise all efforts of handling later transactions would be in vain. This is again out of the range of this article unfortunately 🙂 The second method is to keep the so-called world state in the blockchain and the balance of Alice can be checked in the world state. Of course, the balances are hashed in the world state, it’s in the form of Merkle trees actually.
This article will stop here, leaving so many problems unexplained. How to transform the problem into polynomials? How is this protocol non-interactive? Hopefully I will write about them soon 🙂
A Privacy-Aware Discrimination Prevention Workflow
Website: http://thediscriminationfreemodel.uk/
Discrimination was an issue among humans before the invention of artificial intelligence. However, the rapid development and increasing use of artificial intelligence has raised this concern to algorithms. Algorithms, particularly machine learning algorithms, have involved in or replaced the human’s decision-making process in some scenarios, for example, trading, diagnosing and driving. While this is bringing huge benefit to society, some of the decision-making algorithms are discriminating against certain groups of people. This type of discrimination is called digital discrimination.
At present, this is likely to take place when organisations use algorithms to make decisions on individuals. For example, algorithms are helping to decide whether organisations should hire a person. In 2017, 55% of human resource managers believed artificial intelligence will be involved in human resource decision making in five years. for Individual data submitters, they do not always know how they will be treated when they submit their personal information to organisations and wait for a decision, especially when the decision is made by a machine learning algorithm because machine learning algorithms are normally unexplainable.
Since machine learning algorithms are data-driven, digital discrimination originates from the training process, where the training set is provided by humans. For example, a training data set with gender discrimination tends to inform the algorithm that gender is a good attribute to make classifications with when it notices that most of the people from a gender group are classified to the same category. Therefore, humans should take responsibility and take action to prevent algorithms from learning to discriminate.
Privacy is another human right concern when addressing digital discrimination. While there are some researches on addressing digital discrimination currently, some of the researches do not seem to be practical because their methods compromised privacy at different levels if they are implemented in the real world. In the following chapter, some existing works will be discussed, which proposed tools to prevent discrimination by assuming they have full access to the training data sets or have control over the training processes. In reality, training data sets are likely to be owned and protected by the organisations. Organisations have the right to protect users’ privacy by not disclosing the data set to any other parties. So does the training process, it is difficult to intervene when organisations train their algorithms. This is an important limitation that makes some existing works impractical, unless each organisation does their own research to find out what methods suit their needs and applies them to their data sets, which makes preventing digital discrimination costly.
Among the existing works, those that do not intervene in training processes lie in the category called pre-processing methods. In a nutshell, these methods modify the input of the algorithms. However, from the business perspective, it is less realistic to restrict organisations’ right to collect and use data legally, considering the huge business value of user’s data. Some information that is treated as sensitive information in the decision-making process may be non-sensitive information for other business processes of the organisation. Consequently, a conflict between the need for data of organisations and the need for controlling inputs of decision-making algorithms is shown. This project creates a workflow between individuals and organisations to prevents digital discrimination, in the meanwhile, address this conflict.
The laplace mechanism and exponential mechanism in centralized differential privacy
Introduction
Differential privacy, as a technique to preserve privacy in the data collection process, is categorised into centralised differential privacy (CDP) and local differential privacy (LDP). CDP normally requires a trustworthy third party to collect and process the data before revealing the distribution of the data without compromising the information of each individual entry. This note is about two mechanisms that achieve CDP, the Laplace mechanism and exponential mechanism.
The Laplace mechanism
The Laplace mechanism is for queries of continuous data, i.e. “How many” questions. It adds noise to the numeric result (return_result = true_result + noise), such that adding or removing a single entry from the database does little effect on the result.
To achieve so, the noise can be set to obey the laplace distribution.
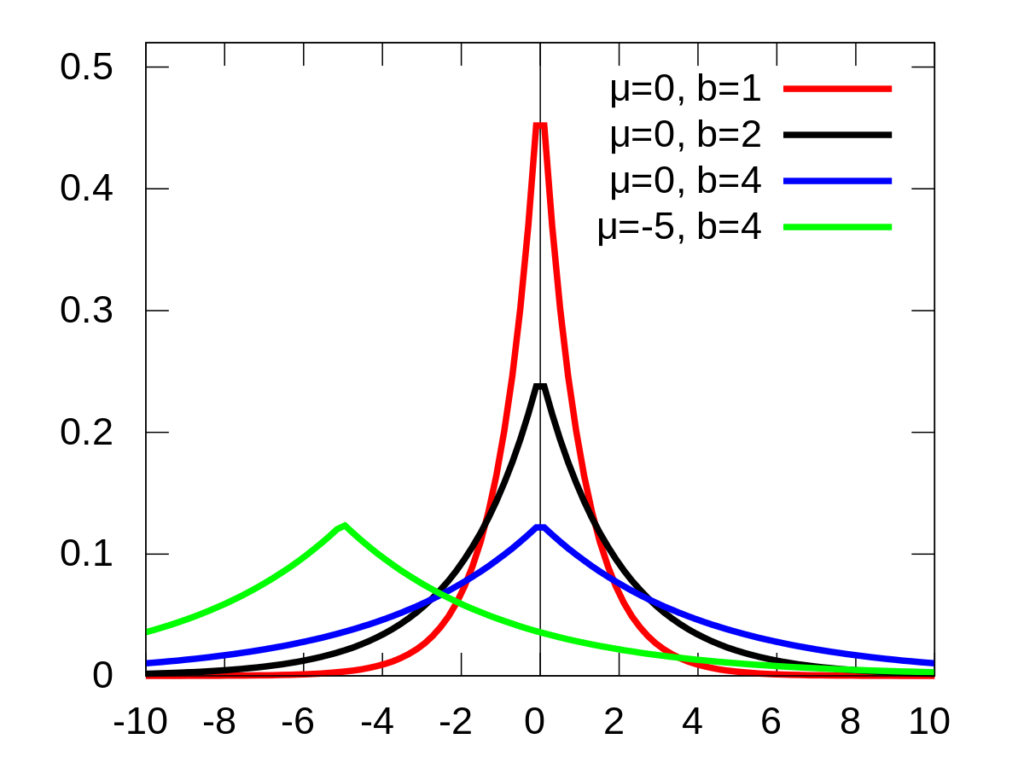
Looking at the three lines where µ=0, it means the noise has a large probability to approach 0, and small probability to be a large positive or negative number.
The parameter b equals to sensitivity/epsilon. Epsilon is the privacy budget in differential privacy. In short, larger epsilon leads to more precise result but lower privacy level, vice versa. Sensitivity is the maximum change that the change of a single entry can bring to the query result. For example, for queries regarding “the number of people”, the sensitivity is 1, because an additional entry of people can change the result by 1 at most.
The exponential mechanism
The exponential mechanism is for queries of discrete data, i.e. “what is” questions. This mechanism renders a probability of returning different results, rather than returning a certain result. For example, for the question “What is the colour that most people like”, if the true answer is red, the mechanism may have 90% chance returning red, 5% chance returning blue, 5% chance returning green, rather than returning red for sure.
Data Encryption Standard (DES) and Advanced Encryption Standard (AES)
DES
DES is a symmetric key algorithm created in the 1970s, when we just started to use computer to run encryption and decryption algorithms.
DES is a block cipher of size 64 bits. With 56 bits key, 64 bits plaintext, DES starts with a initial permutation in a designed, fixed way that reorganize the plaintext, ends with a inverse permutation which is literally the inverse of the initial permutation that recover the order of the text.
Except for the initial permutation and final inverse permutation, DES has identical structure with the Feistel cipher, which I don’t want to write the process in detail:) So let’s focus on the function F and subkey generation parts.
Subkey generation: The 56 bits key will firstly run through a permutation (note that there are a lot of permutations in DES, they are all fixed, published and designed), this will reorder the bits of the key, and break it in two halves of 28 bits, let’s call it C0 and D0, for each round i, Ci-1 and Di-1 will shift one or two bits left (e.g. one bit shift: 10000 to 00001) given i to become Ci and Di, again there is a given table that tells you one or two. Ci and Di, 56 bits togerher, then get another permutation each round (same permutation table for each round), which output 48 bits subkey of each round.
Function F: The 32 bits text (right half of the 64 bits, refer to Feistel cipher) firstly go through an expansion table, in order to XOR with the 48 bits subkey. After applying XOR to the subkey, it goes through a S-box that shorten the text to 32 bits again. The S-box produce 4 bits from every 6 bits, with the first and last bit decide the row of the designed table, and the rest 4 bits decide the column, which gives a 4-bit number in the table.
Finally it goes through a permutation and gives the output. In this function, the expansion, S-box and final permutation use the same table every round, the only difference each round is the subkey.
Decryption for DES is exactly same as encryption except the subkey is used in inverse order.
AES
AES is more recent and still widely used today. It’s a block cipher of size 128 bits. There are three options for the key, 128 bits, 192 bits, 256 bits, corresponding to 10 rounds, 12 rounds and 14 rounds of encryption and decryption. AES works in the unit of bytes instead of bits, so a 128-bit key encryption will have 16 bytes of plaintext and 16 bytes of key.
For a 10 rounds encryption, we firstly take the plaintext and XOR with the original key (not counted as a round), then we start with the first round.
Each round consist of 4 steps, first of all we write the original text as a 4×4 matrix, each element is a byte, the matrix is filled from top to bottom, left to right.
After preparation of the matrix, the first step is to go through a permutation given by a table, similar to those in DES, with the first 4 bits determine the row and last 4 bits determine the column.
Second step is a row transformation, the first row does not move, the second row move 1 bit to the left (the left most bit becomes the right most bit), third row move by 2 bits and last row move by 3 bits.
Third step is a column transformation, the matrix is multiplied by a fixed matrix, but in this matrix multiplication applies different addition and multiplication as we normally do, it is based on a Galois field GF(28), which means no number should be bigger than 28. in a nutshell, addition is simply XOR, multiplication is as follow:
00000010 x a7 a6 a5 a4 a3 a2 a1 a0 = a6 a5 a4 a3 a2 a1 a0 0 if a7 is 0,
else = a6 a5 a4 a3 a2 a1 a0 0 XOR 00011011.
From this we can compute multiplication of any other number, for example, times 00000100 is equal to times 00000010 twice.
Finally comes to the last step, which is simply an XOR with the subkey.
Subkey generation: The initial 128-bit key is devided into 4 parts, each contains 32 bits, name as W0 to W3. Our aim is to generate all the way to W 43 to encrypt 10 rounds.
The rule is: For Wi, if i mod 4 is not 0, then W[i]=W[i-4]⨁W[i-1],
else, W[i]=W[i-4]⨁T(W[i-1]), where T is a three step function:
firstly, leftshift by one, i.e. abcd -> bcda. Secondly, permutation, use the same table as the one in first step encryption to permute the text. At last, XOR with a number given by a table that has different value for different round.
FINALLY DONE.
Decryption of AES apply the inverse of each single step in a reverse order, for the table there is an inverse table, for the matrix there is an inverse matrix, for the row transformation we shift right instead of left.
Substitution Ciphers and Transposition Ciphers in Classic Cryptography
Substitution ciphers and transposition ciphers both belong to symmetric cryptographic system, where encryption key and decryption key are the same, or one can be deducted from the other.
Substitution ciphers
- Caeser cipher
Ceaser cipher is simply substitute all letters to k letters afterwards, where k is the encryption and decryption key, if the plaintext is English then it will be a number between 0 to 25. Easy to use, very easy to break.
Example: ceaser -> fhdvhu, k = 3.
2. Mono-alphabetic subsitution ciphers
Give every letter in the alphabet a subsitution letter, every letter should be use once and only once. So there are 26! possibilities (considering English letters alphabet).
Example:
Plain: ABCDEFGHIJKLMNOPQRSTUVWXYZ
Cipher: DKVQFIBJWPESCXHTMYAUOLRGZN
Compared to Ceaser cipher, Mono-alphabetic subsitution is harder to break in terms of brute-force attack, but still very week because frequency of letters remains, for example the highest frequency letter is more likely to be letter E than any other letters because it is the most frequently used letter in English.
3. Homophonic subsitution cipher
Similar to Mono-alphabetic subsitution ciphers, but provides more than one possible ciphertexts to each plaintext letter.
Example: A = {x, y}, H(x) = {00, 10}, and H(y) = {01, 11}. Then the plaintext xy can be encrypted as 0001 or 1001 or 0011 or 1011.
Although frequency of single letter can be hide, diagram frequencies (pattern of multiple letter) still exist, especially in longer text. Because the provided subsitutes are finite will be reused, at some point some patterns shown before will show again in the ciphertext.
4. Playfair cipher
Make a 5×5 matrix, each box contains one letter (i and j in one box), by selecting a keyword, put the letters of the keyword in the boxes starting at the top left, and fill in the rest boxes with the rest letters.
Example: keyword MONARCHY, matrix as follows
M O N A R
C H Y B D
E F G I/J K
L P Q S T
U V W X Z
After constructing the matrix, break the plaintext into two letters each block, if number of letters are odd, add a selected letter at the end, for example X. Then the rule is:
If both letters fall in the same row, replace each with letter to right, wrapping back to start from end (e.g., “AR” is encrypted as “RM”).
If both letters fall in the same column, replace each with the letter below it, wrapping to top from bottom (e.g., “MU” is encrypted as “CM”).
Otherwise each letter is replaced by the letter in the same row and in the column of the other letter of the pair (e.g., “HS” becomes “BP” and “EA” becomes “IM”, or “JM”, as the encipherer wishes).
Playfair cipher is better than homophonic subsitution, but still the structure of the plaintext is left intact, and not very hard for computer to brute-froce.
5. Polyalphabetic substitution ciphers (Vigenère cipher)
Select a keyword, repeat the keyword until it is as long as the message, there we formed a key where each letter stands for a ceaser cipher, for example, d=3.
Example:
keyword: deceptive
key: deceptivedeceptivedeceptive
plaintext: wearediscoveredsaveyourself
ciphertext: ZICVTWQNGRZGVTWAVZHCQYGLMGJ
this is again better than playfair, but cryptoanalysis methods are still available, for example Kasiski method and Index of coincidence.
6. Vernam cipher and one-time pad
Needs a key as long as the plaintext in terms of bits, do XOR operation, and due to the feature of the XOR operation, when apply XOR to the ciphertext with the key again, plaintext is recovered.
One-time pad is to use the Vernam cipher method, use the key once, then discard and find another one to use.
One-time pad is absolutely safe because it is encrypted in the unit of bits, so no information contains in the ciphertext, and the key is only use once. But it is not to expensive to apply in real life.
Transposition ciphers
- Rail fence cipher
The key of rail fence cipher is a number, the number of depth of the fence. Write the plaintext in the shape of V with the given depth (the key).
Example:
plaintext: WE ARE DISCOVERED FLEE AT ONCE
key: 3
W E C R L T E
E R D S O E E F E A O C
A I V D E N
cipher text:W E C R L T E E R D S O E E F E A O C A I V D E N
Rail fence use the same idea with the Scytale, very week to break.
2. Rotating (turning) grille
Much easier to illustrate with example.
Example:
Plaintext: The Lord is my shepherd. I shall not be in want.
Cut out 9 grid from a 6×6 square, select one from the four of each number to cut, each number should be cut once and only coce.

once prepared, fill the plantext letters in the empty grid one by one, then rotate the paper conterclockwise 90 degree, and continue filling in, until the grille is finished.
ciphertext: mtdhyeisthlbehoeapirhldnelwrainnostt.
Rotating grille is also easy to break since again the frequency of letters remains.
3. Columnar transposition cipher
write the message in a retangle row by row, give a number of sequence to each column and reorganize the text to get the ciphertext, the sequence is the key.
Example:
Key: 4 3 1 2 5 6 7
Plaintext:
a t t a c k p
o s t p o n e
d u n t i l t
w o a m x y z
Ciphertext: TTNAAPTMTSUOAODWCOIXKNLYPETZ
This process can be applied multiple times, then it becomes multiple-stage columnar transposition cipher, which makes it more difficult to break as well.
Linear Algebra Under Geometry Prospective
来自https://www.3blue1brown.com/对于线性代数讲解的整理。
向量除了可以理解为有大小和方向的单位,也可以理解为有序的数字列表。
利用基向量的相加和数乘可以得到的所有向量的集合叫张成的空间(span),如两个二维非共线非零向量张成的空间就是其所在平面。
线性变换(linear transformation) 是以向量作为输入和输出的函数,前提条件是只有原点必须保持不变,而且直线依旧是直线的变换才是线性的。
线性的严格定义是抽象的,它满足可加性和成比例两个条件。可加性是说两个向量变换后相加和相加后变换结果相同,成比例是说向量与标量相乘后变换和向量变换后再与标量相乘结果相同。如果把向量换成函数,这一定义同样适用于函数的求导,所以导数也是线性的。
矩阵可以看作线性变换,一个2×2的矩阵可以看作二维空间的线性变换,其中a和c(左上和左下)两个数就是变换后的基向量i,右边则是变换后的基向量j。
矩阵与向量相乘就可以看作一个线性变换作用与一个向量,得出的结果则是变换后的向量。
复合变换(composition)是多于一个线性变换的组合,既然线性变换是矩阵,符合变换代表的就是矩阵的乘法。矩阵的乘法从右往左计算。
线性变换的行列式(determinant)是线性变换改变面积的比例。行列式为0代表压缩到了低维度,负数代表基向量的翻转。
矩阵的逆(inverse)是抵消矩阵带来的线性变换作用的矩阵。矩阵与逆矩阵相乘就是恒等变换(identity transformation)。
如果一个矩阵的行列式为0,那么它没有逆矩阵。从线性变换的角度它被压缩到底低维度,不能通过线性变换恢复。
变换的结果可以用秩(rank)来描述,变换的结果是几维秩就是几。如果变换没有压缩维度,这使得秩也叫满秩(full rank)。
一个矩阵的列空间(column space)是其与向量相乘的所有可能的输出向量的集。即变换后的基向量张成的空间。可以想象无论怎么压缩零向量都一定会在列空间中。
如果变换非满秩,那么就有多于一个向量被压缩到了原点,这些向量的集合被叫做零空间(null space)或者核(kernel)。
两个维数相同的向量的点积(dot product)是一个向量a在另一个向量b所在的直线上的投影长度与b向量自身的长度的乘积。在数字运算上它是两个向量对应的坐标的乘积的和。这两种计算方法实际上存在巧妙的对应关系。一个向量a必然可以对应一个高维度到一维的不经过缩放的线性变换,这个变换使向量a刚好在变换后张成的空间的这条直线上且基的方向与a同向。此时这个时候向量a的在原来维度中的坐标就是这个线性变换的矩阵乘以它的长度。那么如果让向量b进行这个线性变换,几何视角上看是把b向量投影到了这条直线上,这解释了上述第一个点积的计算方法:b的投影乘以a的长度。数值上来看是把b的坐标乘以这个线性变换再乘以a的长度,后两者则正是a的坐标的数值,只不过现在以一个矩阵的形式呈现,这解释了上述第二种运算方法。
两个向量的叉积(cross product)是以两个向量作为平行四边形两条边组成的平行四边形的面积作为值,符合右手定则(食指为a,中指为b,拇指为结果方向)。叉积考虑顺序,当向量a叉乘向量b且a在b右侧时结果为正,反之为负。计算方式为ab向量坐标组成的矩阵的行列式,不难理解这是因为可以把ab看作线性变换后的两个基,行列式为改变面积的比例,基的叉乘面积本为1,那么改变面积的比例其实就是其面积。
特征向量(eigenvector)是线性变换后不离开原直线的向量。三维空间中线性变换的特征向量就是旋转轴。过程中这些特征向量发生的长度变化叫特征值(eigenvalue)。
ARP(地址解析协议)简介及安全问题
禁止转载,欢迎交流,如有错误请务必指正。
背景
局域网通信除了需要IP地址还需要用到全球每个联网设备都唯一的MAC地址,过程简单来说大概是这样的:局域网中数据包传播的过程中,根据TCP/IP协议,应用层数据封装上传输层包头,IP包头后来到数据链路层加上帧头和帧尾,才能发送出去。这里的帧头包含三个信息,分别是目标MAC地址,源MAC地址,协议类型。其中目标MAC地址就要用到ARP协议来获得。
简介
ARP(Address Resolustion Protocol)地址解析协议作用是在局域网中根据IP地址获得MAC地址。每台联网设备中都会存有ARP表,它记录了已知的IP地址和MAC地址的对应关系。这个表通过不断地和其他人通信来完善,这样一来就不用每次通信都先询问对方的MAC地址。
工作流程
在未知对方MAC地址的情况下,首先设备会发送一个ARP请求报文,向局域网广播,请求目标主机回应,其中也包含了自己的IP地址和MAC地址。目标主机收到后确认是询问自己的MAC地址,便会发出单播应答告知对方。
如在192.168.0/24的网段中,192.168.0.1想与192.168.0.2通信时,192.168.0.1会像整个192.168.0网段所有设备发送ARP请求,每一台设备收到数据包后会检查这个报文中目标IP地址这一项和自己的IP地址是否一致,如果是便会回应对方,由于请求报文中已经包含了对方的MAC和IP,这个数据包就不再需要广播了。
安全相关问题
ARP协议并不是个安全的协议,ARP协议没有校验机制,也就是说收到的信息真伪并不能确定,错误的信息也会被记录,结果轻则无法上网,重则导致信息泄露,被监听,或者篡改。如果局域网中有恶意攻击者,那可能会发生下面的情况:
ARP欺骗:用户A想与用户B通信时会先广播发送ARP请求报文,那么坏人C也能收到这个报文,C并没有丢弃这个请求报文,而是以B的身份回给了A一条消息,把一个错误的MAC地址告诉A,由于ARP的保存机制是收到新的应答就会更新信息,所以只要C在B正常回答了A之后再伪装成B发送回复,A就保存下了错误信息。那么A发给B的数据B就不会收到了。
利用ARP欺骗的中间人攻击:还是上面三个人的情景,如果C回答给A的不是一个不存在的地址,而是C自己的MAC地址,那么A以后想发给B的数据都会给到C手上。如果C再同样的欺骗B,那么A和B的相互通信都会经过C,只要C收到之后再把数据转发给真正的接收方,A和B就能正常通信而且表面上并无异常。除了看到他们的通信数据,C还可以选择性的转发,或者篡改数据后再转发。